![]()
The FoundationDB Book 📖
Welcome! Whether you're building your own datastore with FoundationDB or are simply curious about its capabilities, you've come to the right place.
🚧 This book is a work in progress. We welcome contributions! Feel free to open a pull request with your improvements. 🚧
Who This Book Is For
This book is for developers, architects, and database enthusiasts who want to understand and leverage FoundationDB. It serves as a comprehensive guide, linking to the official documentation and the community forum when deeper dives are needed.
What This Book Covers
- Meet FoundationDB: We start with an introduction to FoundationDB, exploring what makes it unique and why it might be the right choice for your project.
- Getting Started: A hands-on guide to installing FoundationDB and interacting with it using the
fdbclicommand-line tool. - Developing a Layer: Learn the core concepts of building on FDB, from ACID transactions to best practices for data modeling and key design. We'll also look at existing open-source layers for inspiration.
- FoundationDB's Internals: Delve into the architecture of FoundationDB, including its read/write paths and powerful simulation framework.
- The Record Layer: A dedicated look at the Record Layer, a Java library from Apple for building complex data models on FoundationDB.
Meet FoundationDB
This section provides a quick introduction to FoundationDB.
Enter FoundationDB
- The Core: An Ordered, Transactional Key-Value Store
- The Powerhouse: Performance and Reliability
- The Ecosystem: A Foundation for Layers
- A Brief History
- Who Uses FoundationDB?
- TL;DR
As the official overview puts it:
FoundationDB is a distributed database designed to handle large volumes of structured data across clusters of commodity servers. It organizes data as an ordered key-value store and employs ACID transactions for all operations. It is especially well-suited for read/write workloads but also has excellent performance for write-intensive workloads.
Let's unpack what makes FoundationDB unique.
The Core: An Ordered, Transactional Key-Value Store
At its heart, FoundationDB is a distributed, open-source (Apache 2.0) key-value store. Think of it as a massive, sorted dictionary where both keys and values are simple byte strings.
The keys are stored in lexicographical order, which means you can efficiently scan ranges of keys. This simple but powerful feature is the basis for building complex data models. For example:
'user:alice'comes before'user:bob''user:bob'comes before'user:bob:profile'- All keys prefixed with
'table1:'are grouped together, allowing you to simulate rows in a table.
Multi-Key ACID Transactions
The most important feature of FoundationDB is its support for multi-key, strictly serializable transactions. This is a rare and powerful guarantee for a distributed database.
- Transactions: All operations, including reads and writes, are performed within a transaction. These transactions are fully ACID (Atomic, Consistent, Isolated, and Durable), even across multiple machines.
- Multi-Key: A single transaction can read and write multiple, unrelated keys, no matter where they are stored in the cluster.
- Strictly Serializable: This is the strongest isolation level. It ensures that the result of concurrent transactions is equivalent to them running one at a time in some sequential order. This makes writing correct applications dramatically simpler, as you are protected from a wide range of subtle race conditions.
You can find a full list of features and, just as importantly, anti-features in the official documentation.
The Powerhouse: Performance and Reliability
FoundationDB is not just a theoretical model; it's a battle-tested engine built for performance and reliability on commodity hardware.
- Performance: It delivers linear scalability and high performance, often achieving millions of operations per second on a cluster. You can expect sub-millisecond latencies for many workloads without any special tuning.
- Reliability: It is designed to be fault-tolerant, easy to manage, and simple to grow. Its reliability is backed by an unmatched testing system based on a deterministic simulation engine, which we will explore later in this book.
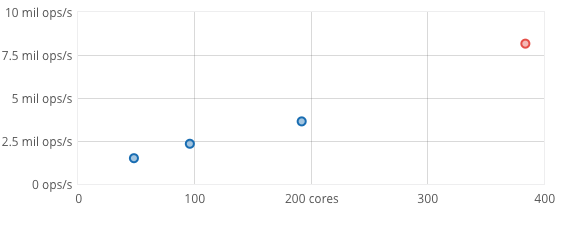
A cluster of commodity hardware scaling to 8.2 million operations/sec on a 90% read, 10% write workload.
The Ecosystem: A Foundation for Layers
Because FoundationDB provides such a powerful and reliable core, it can serve as a universal storage engine—a foundation for building other data models. These are called "layers."
A layer is a stateless component that maps a high-level data model (like a document, graph, or relational model) to FoundationDB's simple key-value model.
graph TD
subgraph "Your Application"
l1("Document Layer")
l2("Graph Layer")
l3("Queue Layer")
end
subgraph "FoundationDB Cluster"
fdb[("Ordered Key-Value Store<br/>ACID Transactions")]
end
l1 -- "stores data in" --> fdb
l2 -- "stores data in" --> fdb
l3 -- "stores data in" --> fdb
This architecture decouples the data model from data storage, allowing developers to focus on building features without reinventing the complexities of a distributed database.
A Brief History
FoundationDB began as a company in 2009. After a successful beta program, version 1.0 was released in 2013. Apple acquired the company in 2015 and subsequently open-sourced the project under the Apache 2.0 license in 2018, making it available to the wider community.
Who Uses FoundationDB?
FoundationDB is the storage engine behind critical systems at major technology companies, including:
- Apple: A massive-scale deployment for iCloud, where it stores billions of logical databases.
- Snowflake: Stores all metadata for its cloud data platform.
- VMware: Used in the Tanzu observability platform.
- And many others, including IBM, eBay, and Epic Games.
TL;DR
FoundationDB is a scalable, distributed key-value store with strictly serializable ACID transactions. It's so powerful and reliable that it serves as a universal foundation for building any data model you can imagine.
Yet Another Database?
- How Are Databases Different?
- The Rise of Polyglot Persistence
- The Anatomy of a Datastore
- The Case for a Shared Storage Engine
- Requirements for a Universal Storage Engine
"Another database? There are so many of them!"
You're right. We live in a golden age of data, which means we have a dizzying number of options for storing it.
According to the Database of Databases, there are nearly 800 different database management systems to choose from. This abundance of choice can be overwhelming.
How Are Databases Different?
When choosing a database, engineers evaluate them against a long list of criteria. This leads to a wide variety of specialized datastores, each optimized for a different purpose. Key differentiators include:
- Data Model: Is it a document, column-family, key-value, graph, or relational database?
- Workload: Is it designed for transactional (OLTP) or analytical (OLAP) workloads?
- Architecture: Is it embedded, single-node, or distributed?
- Transactions: Does it support ACID transactions?
- Query Language: Does it use SQL or a proprietary language?
- Scalability: What are its performance limits?
- Licensing: Is it open-source?
- Features: Does it offer secondary indexes, stored procedures, or materialized views?
The Rise of Polyglot Persistence
This variety of specialized datastores leads developers to use multiple databases in a single application—a pattern sometimes called "polyglot persistence."
For example, a project might require both a relational database for transactional data and a dedicated search index for text search.
Because managing state is complex, a common architectural pattern is to build stateless applications that delegate the complexity of data storage to these specialized, stateful databases.
A typical architecture might look like this:
flowchart TD
app("Stateless Application")
db1("Datastore 1 (e.g., PostgreSQL)")
db2("Datastore 2 (e.g., Elasticsearch)")
app -- uses --> db1
app -- uses --> db2
The Anatomy of a Datastore
While databases differ in many ways, we can simplify their architecture into three core components:
- The Query Language: The interface for interacting with the data.
- The Data Model: The way the data is structured and presented (e.g., relational, document).
- The Storage Engine: The underlying component responsible for durably storing and retrieving data on disk.
For example, PostgreSQL exposes a relational data model via the SQL query language, all running on a storage engine designed for a single node.
Let's update our diagram to show this breakdown:
flowchart TD
subgraph "System Architecture"
app("Stateless Application")
subgraph "Datastore 1"
ql1("Query Language 1") --> dm1("Data Model 1") --> se1("Storage Engine 1")
end
subgraph "Datastore 2"
ql2("Query Language 2") --> dm2("Data Model 2") --> se2("Storage Engine 2")
end
app -- "uses" --> ql1
app -- "uses" --> ql2
end
While the query language and data model are often specialized for a particular use case, what if we could consolidate the storage layer?
The Case for a Shared Storage Engine
Let's imagine we could use a single, powerful storage engine for all our data models.
flowchart TD
subgraph "System Architecture"
app("Stateless Application")
subgraph "Stateless Data Layer 1"
ql1("Query Language 1") --> dm1("Data Model 1")
end
subgraph "Stateless Data Layer 2"
ql2("Query Language 2") --> dm2("Data Model 2")
end
se("Shared Storage Engine")
app -- "uses" --> ql1
app -- "uses" --> ql2
dm1 -- "stores data in" --> se
dm2 -- "stores data in" --> se
end
This design has powerful advantages:
- Operational Simplicity: We only need to manage, scale, and back up one underlying storage system.
- Stateless Components: The layers that provide the data models and query languages can themselves become stateless, simplifying their development and deployment.
However, this places a heavy burden on the shared storage engine. What would it need to provide?
Requirements for a Universal Storage Engine
To be a viable foundation for modern, cloud-native applications, such an engine must be:
- Scalable, Fault-Tolerant, and Highly Available: It must handle growing workloads and survive hardware failures without downtime.
- Transactional: It must provide strong consistency guarantees (like ACID) to allow developers to reason about their data correctly.
- Unopinionated: It should impose a minimal, flexible data model (like an ordered key-value store) to support various data structures on top.
Can such a storage engine exist? Yes. It's called FoundationDB.
Modeling on a Key-Value Store
"If FoundationDB is just a key-value store, how can it power complex applications?"
This is the crucial question. The answer lies in a powerful, common architectural pattern: building rich data models on top of a simple, ordered key-value core. By defining a specific way to encode data structures into keys and values, you can represent almost anything, from relational tables to complex documents and graphs.
This is not a new or niche idea. Many of the most successful and scalable modern databases are built using this exact layered architecture. Let's look at a few examples.
The Pattern: A Tale of Two Layers
Most modern databases can be conceptually divided into two layers:
- The Storage Layer: A low-level engine, often a key-value store, responsible for the distributed storage, replication, and transactional integrity of data.
- The Data Model Layer: A higher-level component that exposes a rich data model (e.g., SQL, Document, Graph) and translates queries into operations on the underlying storage layer.
This separation of concerns allows each layer to do what it does best.
Industry Examples
This layered pattern appears again and again in the architecture of leading databases.
SQL on Key-Value: Google, CockroachDB, and TiDB
Several of the most prominent distributed SQL databases are built on a key-value core.
-
Google's Spanner and F1: Google's database journey shows a clear evolution. Megastore provided ACID semantics on top of the Bigtable key-value store. This evolved into Spanner, which started as a key-value store and grew into a full-fledged relational database. The key insight is that the SQL data model is a layer on top of a scalable, transactional key-value foundation.
-
CockroachDB: As described in their architecture documentation, CockroachDB maps all SQL table and index data directly into its underlying monolithic sorted key-value map.
-
TiDB: The TiDB ecosystem explicitly separates its components. TiDB is the SQL computation layer, while TiKV is the distributed, transactional key-value storage layer. Each SQL row is mapped to a key-value pair in TiKV.
Advanced Indexing on Key-Value
The layered pattern extends beyond just mapping primary table data. Even sophisticated secondary indexing strategies, like those for semi-structured data (JSON) or full-text search, are implemented by modeling the index as a set of key-value pairs.
-
CockroachDB's Inverted Indexes: To allow efficient querying of JSON or array data types, CockroachDB implements inverted indexes. Instead of storing a single key for the whole JSON document, it tokenizes the document and creates multiple key-value entries mapping individual values back to the primary key of the row. This allows for fast lookups based on the contents of the JSON object, a feat not possible with traditional secondary indexes.
-
CouchDB's Map Indexes on FoundationDB: The design for CouchDB's powerful map-based views on FoundationDB provides another clear example. A user-defined
mapfunction processes each document toemitkey-value pairs, which are then stored in FoundationDB to create a secondary index. This entire indexing subsystem is a layer built on top of FDB's core key-value capabilities. -
Azure DocumentDB's Schema-Agnostic Indexing: Before it was known as Cosmos DB, Microsoft's Azure DocumentDB was designed with a powerful indexing subsystem. It could automatically index all data within JSON documents without requiring developers to define a schema or configure secondary indexes. This allowed for real-time queries over schemaless data, a feature implemented by treating the index itself as data in the underlying storage engine.
Multi-Model Databases: Cosmos DB and YugabyteDB
Other databases use this pattern to support multiple data models on a single, unified backend.
-
Azure Cosmos DB: Microsoft's global-scale database projects multiple data models (Document, Graph, Key-Value) over a minimalist core data model. The storage engine itself is agnostic to whether it's storing a document or a graph node.
-
YugabyteDB: Follows a similar layered design, with a query layer that supports both SQL and Cassandra APIs on top of DocDB, its underlying distributed document store, which itself functions as a key-value store.
The Unbundled Database: FoundationDB
All these examples point to a powerful conclusion: many modern databases are, internally, a specialized data model layer tightly bundled with a general-purpose key-value storage engine.
FoundationDB's philosophy is to unbundle these two layers. It provides only the core storage engine, but it makes that engine more powerful and generic than any of the bundled equivalents. It gives you:
- An ordered key-value store.
- Strictly serializable ACID transactions.
- Exceptional performance and proven reliability.
This frees you, the developer, to build any data model layer you can imagine. You get the power of a world-class distributed storage engine without being locked into a specific, high-level data model. FoundationDB is the ultimate realization of the layered database architecture.
A Culture of Correctness
- The Foundation: Flow
- The Engine: Deterministic Simulation
- The Fuel: Generative Testing and Buggify
- The Result: Confidence at Scale
Distributed systems are notoriously difficult to build correctly. The number of possible states, race conditions, and failure modes is astronomical. While tools like Jepsen have become an industry standard for validating the claims of distributed databases, FoundationDB's approach to correctness goes much deeper. It is built on a philosophy of simulation-driven development that is unmatched in the industry.
This chapter explores the layers of this testing strategy, which has allowed FoundationDB to achieve its legendary stability.
The Foundation: Flow
The story of FoundationDB's correctness begins with its programming language: Flow. Developed in the first weeks of the project, Flow is a C++ extension that brings actor-based concurrency to the language. As the engineering team explains:
We’d need efficient asynchronous communicating processes like in Erlang... but we’d also need the raw speed, I/O efficiency, and control of C++. To meet these challenges, we developed... Flow, a new programming language that brings actor-based concurrency to C++11.
Flow isn't just a convenience; it's the critical enabler for the entire testing strategy. By controlling the scheduling of actors and abstracting away I/O, Flow makes it possible to run a deterministic simulation of an entire FoundationDB cluster in a single thread.
The Engine: Deterministic Simulation
This leads to the crown jewel of the testing suite: the simulation framework. For the first 18 months of its development, FoundationDB never sent a single packet over a real network. It was built and tested entirely in simulation.
How does it work?
- Single-Threaded Execution: The entire cluster—every logical process, client, and server—runs as a set of actors within a single OS thread.
- Simulated Interfaces: All external communication, including network, disk, and time, is replaced with a deterministic, in-memory simulation. The network is not reliable; it can be partitioned, delayed, and reordered by the simulator.
- Perfect Reproducibility: Because the simulation is single-threaded and the inputs are controlled by a random seed, any test run is perfectly deterministic. If a test fails with a specific seed, a developer can reproduce the exact sequence of events that led to the failure, down to the scheduling of individual actors.
This allows for a level of testing that is impossible with traditional methods. The team has run the equivalent of a trillion CPU-hours of simulated stress testing, exploring state spaces that would be impossible to cover in the real world.
The Fuel: Generative Testing and Buggify
Deterministic simulation is necessary, but not sufficient. As one engineer put it:
The reason why people write tests is because human beings are astonishingly bad at thinking through all the possible branches of control flow... that very fact means that we're unable to write tests to cover all the things that we actually need to cover.
Instead of trying to write specific tests for every scenario, the FoundationDB team built a system for generating new and interesting tests. A test in FoundationDB is not a simple unit test; it's a combination of a workload (the goal) and a set of chaos agents (things trying to break the goal).
For example, a test might specify a workload of 5,000 transactions per second while simultaneously:
- Clogging the network: Randomly stopping and reordering network packets.
- Killing machines: Randomly rebooting virtual servers.
- Changing the configuration: Forcing the cluster to re-elect its coordinators.
To make this even more powerful, developers use a macro called BUGGIFY. This macro allows them to explicitly cooperate with the simulator by instrumenting the code with potential failure points. For example, a developer can wrap a piece of code in BUGGIFY to tell the simulator, "This is an interesting place to inject a 10-second delay, but only 1% of the time."
This allows the simulation to explore not just external failures (like network partitions) but also internal, heisenbug-like conditions in a controlled and deterministic way.
The Result: Confidence at Scale
The implications of this approach are profound:
- CI as a Brute-Force Weapon: Every pull request is subjected to hundreds of thousands of simulation tests, running on hundreds of cores for hours, before a human even begins a code review.
- Focus on Invention, Not Regression: Developers can focus on building new features, confident that the CI system will relentlessly probe their code for correctness against a chaotic world of failures.
As the original team said, "It seems unlikely that we would have been able to build FoundationDB without this technology." It is this deep, foundational commitment to correctness that makes FoundationDB one of the most robust and trustworthy databases in the world.
Installation
- Do I Need the Client or the Server?
- The Cluster File: Your Key to the Cluster
- ⚠️ A Critical Note on Versioning
This chapter guides you through setting up FoundationDB. While the official documentation provides detailed, platform-specific instructions, this guide will help you understand the components and make the right choices for your setup.
Do I Need the Client or the Server?
The first step is to decide which package you need from the Downloads page.
The Server Package
Install the server package if you want to run a FoundationDB database cluster on a machine. This is for you if you are:
- Setting up a new development environment on your local machine.
- Provisioning a server to be part of a production cluster.
This package contains the core fdbserver binary, which runs the database, and fdbmonitor, which manages the server process.
The Client Package
Install the client package if a machine only needs to connect to an existing FoundationDB cluster. This is for you if you are:
- Building an application that uses a FoundationDB binding (e.g., in Python, Go, or Java).
- Using command-line tools like
fdbclito administer a remote cluster.
This package provides the necessary C libraries (libfdb_c.so) that all language bindings depend on, as well as several administrative tools.
The Cluster File: Your Key to the Cluster
Whether you install the client or the server, you will get a cluster file (e.g., /etc/foundationdb/fdb.cluster). This small text file is critically important:
The cluster file contains the IP addresses and ports of the coordination servers. It's how any client or server finds and connects to the database.
To connect to a cluster, your client machine must have a copy of that cluster's fdb.cluster file. When you set up a new server, one is created for you. When you set up a client to talk to an existing cluster, you must copy the file from the cluster to your client machine.
⚠️ A Critical Note on Versioning
FoundationDB enforces strict compatibility between the client library and server processes. This is a common source of confusion for new users.
The Rule: The installed client library (libfdb_c) and the server binaries (fdbserver) must have the same major and minor version numbers. For example, a client with version 7.1.x can only talk to a server with version 7.1.y. It cannot talk to a server running 7.2.z or 6.3.w.
However, you can connect to a cluster with an older version by specifying the API version in your client code. For example, if your client machine has the 7.4.x libraries installed, you can still connect to a 7.3.z cluster by calling fdb.select_api_version(730) before connecting. This mechanism is particularly useful for facilitating rolling upgrades, allowing clients to be upgraded before the servers.
If you mix incompatible versions without selecting a compatible API version, your application will likely fail to connect, often by hanging indefinitely. The server logs may show ConnectionRejected errors with the reason IncompatibleProtocolVersion. It's crucial to ensure your client machines and server cluster are running compatible versions, or that you are using select_api_version correctly during an upgrade.
Develop on FoundationDB
This section provides a deeper look into the development of FoundationDB.
Key Design: Tuples, Subspaces, and Directories
In a key-value store, the way you structure your keys is one of the most important architectural decisions you will make. Your key schema determines how your data is organized, how efficiently you can query it, and how well your workload will scale. This chapter introduces FoundationDB's powerful, layered abstractions for key management.
The Challenge: Hand-Crafting Keys
At the lowest level, a key is just a sequence of bytes. In many key-value systems, developers are forced to manually craft these byte arrays, a process that is both tedious and error-prone.
Consider storing user data. You might decide on a key structure like (user_id, attribute_name). To implement this, you would need to write code that serializes the user_id (an integer) and the attribute_name (a string) into a single byte array, taking care to handle different data types, lengths, and ordering correctly. This is brittle; a small change in the format can break your application.
FoundationDB provides a much better way.
Layer 1: The Tuple
The most fundamental building block for key design is the Tuple. A tuple is an ordered collection of elements of different types (like strings, integers, and UUIDs). The FoundationDB client libraries provide a pack() function that serializes a tuple into a byte string that correctly preserves type and ordering.
import fdb.tuple
# A tuple containing a string and an integer
user_profile_tuple = ('user', 12345)
# Pack the tuple into a byte key
key = fdb.tuple.pack(user_profile_tuple)
# The result is a byte string suitable for use as a key
# b'\x02user\x00\x1509'
print(repr(key))
# You can unpack the bytes back into the original tuple
unpacked_tuple = fdb.tuple.unpack(key)
assert unpacked_tuple == user_profile_tuple
This simple abstraction solves the manual serialization problem. You can think in terms of structured data, and the tuple layer handles the byte-level representation for you. Because the packing format is standardized across all language bindings, a key packed in Python can be unpacked in Go, Java, or any other language.
Layer 2: The Subspace
Building on tuples, the next layer of abstraction is the Subspace. A subspace is a way to create a dedicated namespace within the database for a particular category of data. It works by defining a prefix tuple that is automatically prepended to all keys packed within that subspace.
This is a powerful organizational tool. For example, you can create separate subspaces for user data, application settings, and logging events.
import fdb.tuple
# Create a subspace for storing user profiles
user_subspace = fdb.Subspace(('users',))
# Now, keys created within this subspace will be prefixed
# with the packed representation of ('users',)
key1 = user_subspace.pack(('alice',))
key2 = user_subspace.pack(('bob',))
# key1 is now b'\x02users\x00\x02alice\x00'
# key2 is now b'\x02users\x00\x02bob\x00'
print(repr(key1))
print(repr(key2))
# You can also use the subspace to unpack a key,
# which strips the prefix automatically.
unpacked = user_subspace.unpack(key1)
assert unpacked == ('alice',)
Subspaces allow you to isolate data and perform range scans over a specific category of information without worrying about colliding with other parts of your keyspace.
Layer 3: The Directory
The highest level of abstraction is the Directory. Directories are a tool for managing subspaces. While you can create subspaces with fixed prefixes (like ('users',)), directories allow you to create and manage them dynamically.
Directories are the recommended approach for organizing the keyspace of one or more applications.
A directory allows you to associate a human-readable path (like ('users', 'profiles')) with a short, randomly generated integer prefix. This has two major benefits:
- Shorter Keys: The generated prefix is much shorter than the packed representation of the full path, saving space.
- Schema Management: You can list, move, and remove directories. Moving a directory is a fast metadata-only change; it doesn't require rewriting all the keys within it.
import fdb
import fdb.directory
fdb.api_version(710)
db = fdb.open()
# Create or open a directory at a specific path
app_dir = fdb.directory.create_or_open(db, ('my-app',))
# Create subspaces within that directory
users_subspace = app_dir.create_or_open(db, ('users',))
logs_subspace = app_dir.create_or_open(db, ('logs',))
# The key for the 'users' subspace might be b'\x15\x01', a much
# shorter prefix than packing the full path.
print(repr(users_subspace.key()))
# You can now use this subspace as before
@fdb.transactional
def set_user(tr, name):
tr[users_subspace.pack((name,))] = b'some_profile_data'
set_user(db, 'charlie')
By using these three layers—Tuples for serialization, Subspaces for namespacing, and Directories for management—you can build sophisticated and maintainable data models on top of the simple key-value interface.
Best practice for storing structured data
When storing structured data like JSON objects in FoundationDB, you have two primary approaches. Each has its own set of trade-offs.
Store the object as a blob
If you decide to store the object as a single blob, you will need to pay the cost of reading the entire object back, even if you only need to access a single field. This approach can be efficient if you always read the entire document anyway (e.g., returning it as JSON via a REST API).
However, if you have a few fields that are updated frequently (like a last_accessed_timestamp), this option will incur a large serialization overhead. Furthermore, due to the value size limit in FDB, you may need to split a large object into multiple key-value pairs.
On the other hand, storing data as a single blob (or even more aggressively, batching multiple objects into one) provides an opportunity to compress the data on disk. FoundationDB does not provide built-in compression for key-value data, so this would need to be handled at the application layer.
Store the object as separate key-value pairs
When an object is stored as separate key-value pairs, random access to a single field becomes much faster and more efficient. This approach makes implementing technologies like GraphQL more feasible.
For example, a JSON object like:
{
"id": 123,
"name": "John Doe",
"email": "john.doe@example.com"
}
Could be stored as:
(123, "name") = "John Doe"
(123, "email") = "john.doe@example.com"
However, this comes at a cost: increased disk space usage. There is little to no opportunity to compress the data on disk when using this method.
Conclusion
If you’re building a generic document database, it’s challenging to pick one strategy that works best for all use cases. You might consider making the storage strategy configurable, or even adaptive based on the workload.
For example, the FDB Document Layer allows data to be stored fully expanded or packed into 4k blocks.
To learn more about compressing data in this context, you can read the discussion in this forum post.
Learning from the Community: Open-Source Layers
One of the best ways to learn how to build on FoundationDB is to study existing, production-proven layers. A "layer" is simply a library or service that provides a higher-level data model on top of FoundationDB's ordered key-value store. By examining how these layers map their data models to keys and values, you can gain invaluable insights for your own projects.
Here are some of the most prominent open-source layers developed by the FoundationDB community.
The Record Layer
The Record Layer provides a structured, record-oriented data store on top of FoundationDB, similar to a traditional relational database. It is used in production at Apple to power CloudKit.
- GitHub Repo: foundationdb/fdb-record-layer
- Academic Paper: FoundationDB Record Layer
- Key Videos:
- FoundationDB Record Layer: Open Source Structured Storage on FoundationDB (Nicholas Schiefer, Apple)
- Using FoundationDB and the FDB Record Layer to Build CloudKit (Scott Gray, Apple)
The Document Layer
The Document Layer implements a MongoDB®-compatible API, allowing you to store and query JSON documents within FoundationDB.
- GitHub Repo: FoundationDB/fdb-document-layer
- Key Video:
- FoundationDB Document Layer (Bhaskar Muppana, Apple)
The ZooKeeper Layer
This layer implements the Apache ZooKeeper API, providing a distributed coordination service built on FoundationDB.
- GitHub Repo: pH14/fdb-zk
- Key Video:
- A ZooKeeper Layer for FoundationDB (Paul Hemberger, HubSpot)
The Time-Series Layer
This is an experimental, high-performance layer written in Go, designed specifically for storing and querying time-series data with high compression.
- GitHub Repo: richardartoul/tsdb-layer
- Key Video:
Warp 10
Warp 10 is a powerful platform for managing time-series data. While it was not originally built on FoundationDB, version 3.0 and later versions have adopted it to replace HBase. This change was motivated by a desire to simplify operations and eliminate the dependency on the Hadoop ecosystem.
- GitHub Repo: senx/warp10-platform
- Key Blog Post: Introducing Warp 10 3.0!
Best Practices and Pitfalls
This chapter provides a collection of best practices, advanced techniques, and common pitfalls to help you build robust, production-ready layers on FoundationDB.
Transaction Management
Use Timeouts and Retry Limits
Most language bindings provide a run or transact method that automatically handles the retry loop for you. However, to prevent transactions from running indefinitely, it is critical to configure two options:
- Timeout: Set a timeout in milliseconds. If the transaction takes longer than this to commit, it will be automatically cancelled. This is a crucial backstop for preventing stuck application threads.
- Retry Limit: Set a maximum number of retries. This prevents a transaction from retrying endlessly in the case of a persistent conflict or a live-lock scenario.
These options should be set on every transaction to ensure your application remains stable under load.
Set Transaction Priority
FoundationDB supports transaction priorities to help manage workloads.
- Default: The standard priority for most latency-sensitive, user-facing operations.
- Batch: A lower priority for background work, such as data cleanup or analytics. Batch priority transactions will yield to default priority transactions, ensuring that they don't interfere with your main application workload.
- System Immediate: The highest priority, which can block other transactions. Its use is discouraged outside of low-level administrative tools.
Observability
Tag Your Transactions
FoundationDB allows you to add a byte-string tag to any transaction. This is an invaluable tool for observability and performance management. You can use tags to identify different types of workloads (e.g., user_signup, post_comment). The fdbcli tool can then be used to monitor the rate of transactions with specific tags and even throttle them if they are causing excessive load.
See the official documentation on Transaction Tagging for more details.
Enable Client Trace Logs
By default, clients do not generate detailed trace logs. To debug performance issues, you can enable them by setting the TraceEnable database option. You can then add a DebugTransactionIdentifier to a specific transaction and set the LogTransaction option to get detailed, low-level logs about its execution, including all keys and values read and written.
Advanced Techniques
The metadataVersion Key
The special key \xFF/metadataVersion is a cluster-wide version counter that can be used to implement client-side caching. Its value is sent to clients with every read version, so reading it does not require a round-trip to a storage server. A layer can watch this key to know when to invalidate a local cache.
Note: If you write to the metadataVersion key, you cannot read it again in the same transaction.
The TimeKeeper
The Cluster Controller maintains a map of recent read versions to wall-clock times. This can be accessed by scanning the key range beginning with \xFF\x02/timeKeeper/map/. This can be useful for approximating a global clock.
Special Keys
Keys prefixed with \xFF\xFF are “special” keys that are materialized on-demand when read. The most common example is \xFF\xFF/status/json, which returns a JSON document containing the cluster's status.
See the official documentation on Special Keys for more details.
Common Pitfalls: The Directory Layer
The Directory Layer is a powerful tool, but it has several sharp edges that developers must be aware of:
- Concurrent Mutations: Modifying the same directory (e.g., creating two different subdirectories within it) in multiple, concurrent transactions is not safe and can lead to corruption.
- Metadata Hotspots: Opening a directory with a long path requires one read per path element for every transaction. This can create a hotspot on the directory's internal metadata subspace.
- Multi-Cluster Deployments: The directory prefix allocator is not safe for multi-cluster deployments and can allocate the same prefix in different clusters, leading to data corruption if the data is ever merged.
- Redwood and Prefix Compression: The Redwood storage engine (new in 7.0) provides native key-prefix compression. This offers many of the same space-saving benefits as the Directory Layer without the associated complexity and caveats. For new projects, especially those using Redwood, consider whether you can use subspaces with descriptive prefixes directly instead of relying on the Directory Layer.
Operate FoundationDB
This section provides a deeper look into the operation of FoundationDB.
Anatomy of a Cluster: Roles
- The Coordinator
- The Cluster Controller
- The Proxies
- The Resolver
- The Log Server
- The Storage Server
- The Data Distributor
FoundationDB's architecture is built on a collection of specialized, stateless roles. This separation of concerns is a key reason for its high performance, scalability, and fault tolerance. A running fdbserver process can dynamically take on any of these roles as needed. Understanding them is the first step to understanding how FoundationDB works.
Here are the core roles in a FoundationDB cluster:
The Coordinator
The Coordinator is the first process that any client or server connects to when joining the cluster. Its primary job is to manage the cluster file, a small, durable text file that contains the IP addresses and ports of the coordinators themselves. The coordinators elect a Cluster Controller, which serves as the singleton brain of the cluster.
The Cluster Controller
The Cluster Controller is the authoritative monitor for the entire cluster. There is only one active Cluster Controller at any time. It is responsible for:
- Monitoring the health of all other
fdbserverprocesses. - Recruiting new processes to take on roles as needed (e.g., if a Log Server fails).
- Orchestrating recovery when a process fails.
The Proxies
FoundationDB splits the traditional role of a proxy into two distinct components: the GRV Proxy and the Commit Proxy. This separation allows for better scaling and specialization. Clients first interact with a GRV proxy to start a transaction and then with a Commit Proxy to commit it.
The GRV Proxy
The GRV Proxy (Get Read Version Proxy) is responsible for one critical task: providing a Read Version to a client when it begins a transaction. To do this, the GRV proxy communicates with the Master to get the latest committed version from the transaction system. This ensures that the transaction gets a consistent snapshot view of the database. The Ratekeeper process can apply backpressure by slowing down the rate at which GRV Proxies issue read versions, which helps manage cluster load.
The Commit Proxy
The Commit Proxy is the front door for all transaction commits. When a client commits a transaction, it sends its read and write sets to a Commit Proxy. The Commit Proxy orchestrates the second half of the transaction lifecycle:
- Getting a Commit Version from the Master.
- Sending the transaction's read and write sets to the Resolver to check for conflicts.
- If the transaction is valid, sending its mutations to the Log Servers to be made durable.
- Reporting the final commit status back to the client.
Because both proxy types are stateless, you can add more of them to the cluster to increase both the number of transactions that can be started and the overall commit throughput.
The Resolver
The Resolver is the component that enforces serializability. During the commit process, the Commit Proxy sends the transaction's read and write sets to the Resolver. The Resolver checks if any of the keys in the read set have been modified by another transaction that has committed since the current transaction's read version was assigned. If a conflict is found, the transaction is rejected, and the client must retry.
The Log Server
The Log Server is the heart of FoundationDB's durability guarantee. It implements the transaction log. When a transaction is ready to be committed, its mutations are sent to the Log Servers, which write them to durable storage (typically an SSD) before the commit is acknowledged to the client. The Log Servers do not need to apply the changes to the main data store; they just need to record them.
The Storage Server
The Storage Server is responsible for storing the data. Each Storage Server holds a set of key ranges (shards). It serves read requests from clients and receives committed mutations from the Log Servers, applying them to its in-memory B-tree and eventually writing them to disk. Storage Servers are the workhorses of the cluster, and you can add more of them to increase both storage capacity and I/O performance.
The Data Distributor
The Data Distributor is a background role responsible for ensuring that data is evenly distributed and replicated across all of the Storage Servers. It monitors the size and workload of each shard and will automatically move data between servers to prevent hotspots and ensure fault tolerance. It is also responsible for initiating data replication and healing the cluster after a Storage Server fails.
Guidelines for Choosing Coordinators
Unlike most roles in the cluster, which are assigned dynamically, coordinators must be configured statically. This requires careful consideration to ensure your cluster is both fault-tolerant and performant.
Overview
Coordinators are responsible for three critical functions:
- Electing the Cluster Controller: The cluster controller is the leader of the cluster. This election is an iterative process, and having too many coordinators can increase the probability of failure in each round, slowing down the election process significantly.
- Storing Global State: During a recovery, this state is read, locked, and rewritten to all coordinators. The more coordinators you have, the longer this process takes, which can increase your recovery times.
- Facilitating Client Connections: Clients discover the cluster controller through the coordinators. While this path is optimized, in the worst case, a client may need to communicate with all coordinators, making new connections slower.
Losing a majority of your coordinators will cause the database to become unavailable. However, having more coordinators than necessary can harm performance and make operations more complex.
Recommended Coordinator Counts
The goal is to have enough coordinators to meet your fault-tolerance goals without adding unnecessary overhead.
-
Single Data Center: For a single-DC configuration with a replication factor of
R, the recommended number of coordinators is2*R - 1. This configuration can tolerate the failure ofR-1coordinators while still maintaining a majority. -
Multi-Data Center: For multi-DC deployments, you typically want to be resilient to the loss of at least one data center plus one additional machine failure. For these scenarios, we recommend 9 coordinators, spread evenly across at least 3 DCs. This ensures that no single DC has more than 3 coordinators. If you lose one DC and one additional machine, you would lose at most 4 of your 9 coordinators, leaving a majority available.
-
Two Data Centers: If you are only storing data in two DCs, we recommend provisioning 3 processes in a third data center to serve exclusively as coordinators.
Determining Which Processes to Use
When selecting which fdbserver processes will act as coordinators, follow two rules:
- Unique Fault Domains: Every coordinator should be on a different physical machine or fault domain (and thus have a different
zoneid). - Even Distribution: Coordinators should be spread as evenly as possible across data centers and racks.
Following these guidelines will help ensure your cluster achieves its desired level of fault tolerance.
Upgrading FoundationDB
Upgrading a FoundationDB cluster can be a challenging process, but with the right procedure, it can be accomplished with zero downtime.
Overview
The main challenge is that the internal wire protocol used for communication between server processes is not guaranteed to be stable across different minor versions. This means that during a minor version upgrade (e.g., from 6.1 to 6.2), all fdbserver processes must be restarted with the new binaries simultaneously.
Clients must also use a protocol-compatible library to connect. To avoid client outages, FoundationDB supports a multi-version client feature, allowing an application to load both old and new client libraries at the same time.
This guide outlines a safe, zero-downtime upgrade process, assuming you are running fdbserver through fdbmonitor.
Server Upgrade Process
The high-level process is as follows:
-
Install New Binaries: Install the new
fdbserverbinaries alongside the old ones. It's a good practice to place them in versioned directories, for example:- Old:
/usr/bin/fdb/6.1.12/fdbserver - New:
/usr/bin/fdb/6.2.8/fdbserver
- Old:
-
Update Monitor Configuration: Update the
fdbmonitor.conffile to point to the newfdbserverbinary path. -
Restart the Cluster: Using the old version of
fdbcli, issue a coordinated restart of the cluster:fdbcli --exec 'kill; kill all; status' -
Verify Health: Using the new version of
fdbcli, connect to the database and confirm that the cluster is healthy and running the new version.
To minimize the risk of processes restarting organically with the new binary before the coordinated kill, you should set kill_on_configuration_change=false in your fdbmonitor.conf and minimize the time between steps 2 and 3.
Client Upgrade Process
To ensure clients remain connected during the server upgrade, you must prepare them ahead of time using the multi-version client feature.
-
Install New Client Library: Install the new client library (
.soor.dylib) into a dedicated directory. The filename should include the version (e.g.,/var/lib/fdb-multiversion/libfdbc_6.2.8.so). -
Configure Environment Variable: Set the
FDB_NETWORK_OPTION_EXTERNAL_CLIENT_DIRECTORYenvironment variable in your client application's environment to point to this directory (e.g.,/var/lib/fdb-multiversion). -
Restart Client Application: Bounce your client application to make it load the new library in addition to the one it's already using.
-
Verify Client Compatibility: Before upgrading the servers, you can check the database status JSON (
status json) to confirm that all clients have loaded a compatible protocol version. Thecluster.clients.supported_versionsfield will list all protocol versions supported by connected clients. -
Perform Server Upgrade: Once all clients are ready, proceed with the server upgrade steps described above.
-
Clean Up: After the server upgrade is complete and stable, you can update your client applications to use the new library as their primary version and remove the old library files from the multi-version directory.
Upgrading Other Binaries
Tools like fdbbackup and fdbdr must also be protocol-compatible. You should upgrade these binaries after the main cluster upgrade is complete. There will be a temporary lag in backup and disaster recovery operations until these components are also running the new version.
Data Distribution and Movement
FoundationDB automatically manages the distribution of data across the cluster. This process is crucial for ensuring fault tolerance, balancing load, and managing storage space efficiently.
Reasons for Data Movement
FoundationDB will only move data for a few specific reasons:
- To restore replication after a failure: If a storage server fails, the data it was responsible for becomes under-replicated. The data distribution system will create new copies of that data on other servers to restore the desired replication level.
- To manage shard size: The system aims to keep data shards within an optimal size range (roughly 125MB to 500MB). It will split shards that grow too large and merge shards that become too small.
- To handle write hotspots: If a particular shard experiences a high volume of writes, it may be split to distribute the write load.
- To balance storage load: The system will move data to ensure that the total bytes stored are balanced evenly across all storage servers in the cluster.
Notably, data distribution does not balance the load based on high read traffic. When moving a shard, it only considers the total bytes stored, not the read or write traffic on that shard. This means it's possible for multiple high-traffic ranges to be assigned to the same storage server.
Observing Data Movement
You can monitor data movement activity through the fdbcli status command. The output provides key metrics:
Data:
Replication health - Healthy
Moving data - 0.043 GB
Sum of key-value sizes - 88 MB
Disk space used - 382 MB
The Moving data field shows how much data is currently in flight. There is no ETA published for data movement, and it's normal for it to be happening constantly, especially in a cluster with a high write workload.
Adjusting Distribution Speeds
There are no simple controls for adjusting the speed of data distribution. While some configuration knobs exist (e.g., DD_MOVE_KEYS_PARALLELISM, MOVE_KEYS_KRM_LIMIT), changing them is strongly discouraged unless you have a specific need and understand the potential consequences. These settings must be applied at the startup of your fdbserver processes and should be handled with extreme caution.
The Record Layer
This section provides a deeper look into the Record Layer of FoundationDB.
What is the Record Layer?
The FoundationDB Record Layer is an open-source library that provides a record-oriented data store with semantics similar to a relational database, implemented on top of FoundationDB. Think of it as a "middle layer" that provides common database-like features, making it easier to build complex, scalable applications on FDB.
It was created to solve the common and difficult challenges that arise when building a structured data layer on top of a key-value store, such as schema management, indexing, and query execution, especially in a multi-tenant environment.
Core Design Principles
The Record Layer is built around a few core principles:
-
Structured, Schematized Data: It stores structured records using Google's Protocol Buffers. This provides a robust way to define a schema and evolve it over time.
-
Stateless Architecture: The layer itself is completely stateless. All state is stored in FoundationDB or returned to the client (e.g., as a
continuation). This simplifies scaling and operation, as any server can handle any request. -
Streaming Queries: The Record Layer is designed for a streaming model. For example, it only supports ordered queries (like SQL's
ORDER BY) if there is an index that can produce the data in the requested order. This avoids large, stateful in-memory operations and makes performance predictable, favoring fast OLTP workloads over analytical OLAP queries. -
Extensibility: The layer is highly extensible. Clients can define their own custom index types, index maintainers, and query planner rules, allowing them to tailor the database's behavior to their specific needs.
The "Record Store": A Logical Database
A key abstraction in the Record Layer is the Record Store. A Record Store is a logical, self-contained database that holds all of a tenant's records, indexes, and metadata. This entire logical database is stored within a single, contiguous key-space in FoundationDB, called a subspace.
This design is a perfect fit for multi-tenant applications. For example, Apple's CloudKit uses this model to provide a distinct logical database for every application on every user's device—billions of independent databases in total. Because a Record Store is just a range of keys, it can be easily moved between FDB clusters for load balancing.
Key Technical Features
The Record Layer abstracts away several complex engineering problems by leveraging FoundationDB's core features.
Key Expressions for Flexible Indexing
Indexes are defined using key expressions, which are functions that specify how to extract data from a record to form an index key. Key expressions can be simple (e.g., a single field's value) or complex. They can:
- Concatenate multiple fields together.
- Fan out by creating multiple index entries from a single record, such as indexing each element in a repeated field (a list).
- Nest to index fields within a sub-record.
This provides a powerful and flexible way to create indexes on highly structured, nested data.
Online Index Building
Building an index on a large, live dataset is a hard problem. The Record Layer's online indexer handles this gracefully. When a new index is added, it transitions through several states:
- Write-only: The index is maintained for all new and updated records, but it cannot yet be used for queries.
- Building: A background process scans all existing records in batches, adding their corresponding entries to the index. This process is transactional, fault-tolerant, and resumable.
- Readable: Once the background build is complete, the index is marked as readable and can be used by the query planner.
Advanced Index Types
The Record Layer includes several powerful, built-in index types:
- VALUE: A standard index that maps the value from a key expression to the record's primary key.
- ATOMIC: An index that uses FoundationDB's atomic mutations to maintain aggregate statistics without transaction conflicts. This is used for
SUM,COUNT,MAX, andMINindexes. - VERSION: An index on the commit version of a record. This creates a conflict-free, totally-ordered change log, which is ideal for synchronization. The version is a unique 12-byte value: 10 bytes from the FDB commit version and 2 bytes from a transaction-local counter in the Record Layer.
- RANK: An index that can answer questions like, "what is the Nth record in a given order?" or "what is the rank of this specific record?"
- TEXT: A full-text index for searching for words or phrases within a text field.
Query Continuations for Resource Control
To prevent any single request from consuming too many resources, all long-running operations are pausable. When a query hits a predefined limit (e.g., number of records scanned or time elapsed), it stops and returns the results it has found so far, along with an opaque continuation.
This continuation captures the exact state of the query. The client can pass it back in a new request to resume the query exactly where it left off. This makes the system highly scalable and resilient, as it allows for fine-grained control over resource usage.
Further Reading
- Paper: FoundationDB Record Layer: A Multi-Tenant Structured Datastore (SIGMOD '19)
- Video: FoundationDB Record Layer: Open Source Structured Storage on FoundationDB (FDB Summit 2018)
- Video: Using FoundationDB and the FDB Record Layer to Build CloudKit (FDB Summit 2018)
QuiCK: A Queuing System in CloudKit
QuiCK is a distributed, transactional queuing system developed for and integrated into Apple's CloudKit. It is built on top of FoundationDB and the Record Layer. Its primary purpose is to reliably manage deferred, asynchronous tasks that are generated by CloudKit operations, such as updating search indexes, sending push notifications, or performing data compaction.
The Challenge: Queuing at CloudKit Scale
CloudKit needed a way to manage a massive volume of asynchronous tasks without using a separate, external queuing system. Using an external system like Kafka or RabbitMQ presented several major challenges:
-
No Transactionality: It's impossible to have a single atomic transaction that spans both CloudKit's database (FDB) and an external queue. For example, if a user shares a Keynote document, the system must both update access permissions in the database and enqueue a task to send a push notification. Without a transactional queue, the database update could succeed while the task enqueue fails, leaving collaborators unaware of the share.
-
Data Migration: CloudKit frequently moves user data between FDB clusters for load balancing. If a user's tasks were in a separate system, this would create a coordination nightmare. For example, if a user deletes a folder in iCloud Drive and their database is then moved to a new datacenter, their queued deletion task could be left behind, unable to find the data it's supposed to act on.
-
Tenancy Mismatch: CloudKit has a fine-grained tenancy model with billions of logical databases (one for each user of each app). Traditional queuing systems are designed for thousands of topics, not billions. Mapping the CloudKit model to a traditional queue would be impossible.
-
Operational Complexity: An external system would be another massive, stateful service to provision, monitor, and operate alongside the hundreds of FDB clusters that power CloudKit.
To solve these issues, the team built QuiCK directly into CloudKit, storing queued tasks right alongside the user data they pertain to.
Core Design and Technical Features
QuiCK's design overcomes the traditional concerns of building a queue on a database (like hotspots and consumer contention) through several key innovations.
Two-Level Sharding
QuiCK avoids hotspots by sharding at an extreme scale:
-
Level 1: Queue Zones: The primary level of sharding consists of tens of billions of individual queues, called Queue Zones. Each tenant (a user of a CloudKit app) gets their own queue within their logical database. This means one tenant's activity can never create a hotspot that affects another.
-
Level 2: Cluster Queues: To help consumers find work efficiently, a second, higher-level queue exists on each FDB cluster. When a task is first enqueued into a tenant's previously empty Queue Zone, the same transaction also adds a pointer to that zone into the higher-level Cluster Queue. Consumers poll the Cluster Queue to find these pointers, which efficiently leads them to tenants with work to be done.
Fault-Tolerant Leases via Vesting Time
To prevent multiple consumers from processing the same item, QuiCK uses a clever, fault-tolerant leasing mechanism. Instead of locking or immediately deleting an item, a consumer takes a lease by updating the item's vesting time to some point in the future (e.g., 5 minutes from now). This makes the item invisible to other consumers for the duration of the lease. If the consumer processes the item successfully, it deletes it. If the consumer crashes, the lease simply expires, and the item automatically becomes visible again for another consumer to pick up.
Polling for Fairness and Efficiency
Given the massive number of queues, a push-based model is not feasible. Instead, QuiCK uses a polling-based model where a shared pool of consumers asks for work when they have capacity. This allows QuiCK to implement scheduling and fairness policies, deciding which queue to service next based on tenant priority or resource usage, preventing a single user from starving others.
Leveraging FoundationDB and the Record Layer
QuiCK is a powerful example of building a complex subsystem on top of the FDB/Record Layer stack:
- Transactional Integrity: Enqueuing a task and adding a pointer to the cluster queue are atomic operations within a standard FDB transaction.
- Exactly-Once Semantics: For tasks that only modify the database (no external side effects), QuiCK can achieve exactly-once semantics by processing the task and deleting it from the queue within a single transaction.
- Indexed Queues: The Record Layer's secondary indexes are used to order items within a Queue Zone by priority and vesting time, so consumers always process the most important item first.
Further Reading
- Paper: QuiCK: A Queuing System in CloudKit (SIGMOD '21)
- Video: QuiCK: A Queuing System in CloudKit (SIGMOD '21)
FoundationDB Internals
This section provides a deeper look into the internal architecture and components of FoundationDB.
The Write Path
Understanding the life of a write transaction is key to understanding how FoundationDB provides its powerful guarantees of strict serializability and durability. The process involves a carefully choreographed dance between several cluster roles.
Let's walk through the journey of a transaction from the moment a client calls commit() to the point where it is safely stored in the database.
sequenceDiagram
participant Client
participant Proxy
participant Resolver
participant Log Server
participant Storage Server
Client->>+Proxy: commit(read_set, write_set)
Proxy->>Proxy: 1. Get Read Version
Proxy->>+Resolver: 2. Resolve(read_version, read_set, write_set)
Resolver-->>-Proxy: OK (no conflicts)
Proxy->>+Log Server: 3. Log(commit_version, write_set)
Log Server-->>-Proxy: 4. Durable
Proxy-->>-Client: 5. Commit Successful
loop Later
Storage Server->>+Log Server: Pull mutations
Log Server-->>-Storage Server: Mutations
Storage Server->>Storage Server: Apply to B-Tree
end
The Steps of a Commit
-
Get Read Version: When the transaction is ready to be committed, the client library sends it to a Proxy. The first thing the Proxy does is request a Read Version from the Cluster Controller. This version number establishes the logical point in time at which the transaction's reads occurred.
-
Conflict Resolution: The Proxy sends the transaction's Read Version, its read set (the list of keys it read), and its write set to the Resolver. The Resolver checks if any of the keys in the read set have been written to by another transaction that committed after this transaction's Read Version. If a conflict is detected, the Resolver tells the Proxy to reject the transaction, and the client must retry.
-
Logging for Durability: If the Resolver finds no conflicts, the Proxy assigns the transaction a Commit Version (which will be higher than its Read Version) and sends the transaction's write set (the keys and values to be written) to the Log Servers.
-
Durable Commit: The Log Servers write the transaction's mutations to their durable, on-disk transaction logs. Once a quorum of Log Servers has confirmed that the data is safely on disk, they respond to the Proxy. At this point, the transaction is considered durable. Even if the entire cluster lost power, the transaction would be recovered.
-
Success! The Proxy, having received confirmation from the Log Servers, reports back to the client that the commit was successful.
The Final Step: Data Storage
Notice that the Storage Servers were not involved in the critical commit path. This is a key design decision that makes commits extremely fast.
After the transaction is durable, the Storage Servers will eventually pull the new data from the Log Servers and apply the mutations to their own on-disk B-trees. This process happens asynchronously in the background and does not block new incoming transactions. This separation of the transaction log from the primary data store is a pattern known as Command Query Responsibility Segregation (CQRS) and is fundamental to FoundationDB's performance.
The Read Path
FoundationDB's read path is designed to be highly scalable and efficient. Unlike the write path, which is coordinated through a central set of proxies, the read path is almost entirely decentralized. This allows the cluster to serve a massive number of concurrent reads without creating bottlenecks.
Here is a high-level overview of how a read operation works:
sequenceDiagram
participant Client
participant Proxy
participant Storage Server
Client->>+Proxy: 1. Get Read Version
Proxy-->>-Client: read_version
Client->>Client: 2. Locate Storage Server (from cache)
Client->>+Storage Server: 3. Read(key, read_version)
Storage Server-->>-Client: Value
The Steps of a Read
-
Get Read Version: When a client begins a transaction, the first thing it does is request a Read Version from a Proxy. This version is a timestamp that represents a consistent, immutable snapshot of the entire database. All reads within the transaction will be served from this snapshot, which is the foundation of FoundationDB's snapshot isolation.
-
Locate the Storage Server: The client library maintains a local cache that maps key ranges to the Storage Servers responsible for them. When the client needs to read a key, it uses this cache to determine which Storage Server to contact. This lookup is extremely fast and does not require a network round-trip.
-
Read from the Storage Server: The client connects directly to the appropriate Storage Server and requests the value for the key at the transaction's Read Version. The Storage Server uses its in-memory B-tree and on-disk data files to find the correct version of the value and return it to the client.
Key Takeaways
- Decentralized and Scalable: Because clients read directly from Storage Servers, read throughput can be scaled horizontally simply by adding more Storage Servers to the cluster.
- Snapshot Isolation: The use of a Read Version ensures that a transaction sees a perfectly consistent view of the database, even as other transactions are being committed concurrently. Your reads are never "dirty."
- Low Latency: By caching the mapping of keys to Storage Servers, the client can avoid extra network hops and read data with very low latency.